 Kryštof Komanec
Kryštof KomanecCreating complex, high-quality documents in FAIR Wizard used to mean dealing with deeply nested UUID paths, manual reply chains, and brittle conditionals. It worked, but made templates verbose, error-prone, and hard to maintain.
Now, there is a better way.
Instead of relying on hardcoded UUID chains, you can annotate your Knowledge Model items directly in the KM Editor. These annotations are then extracted automatically into structured objects for your templates.
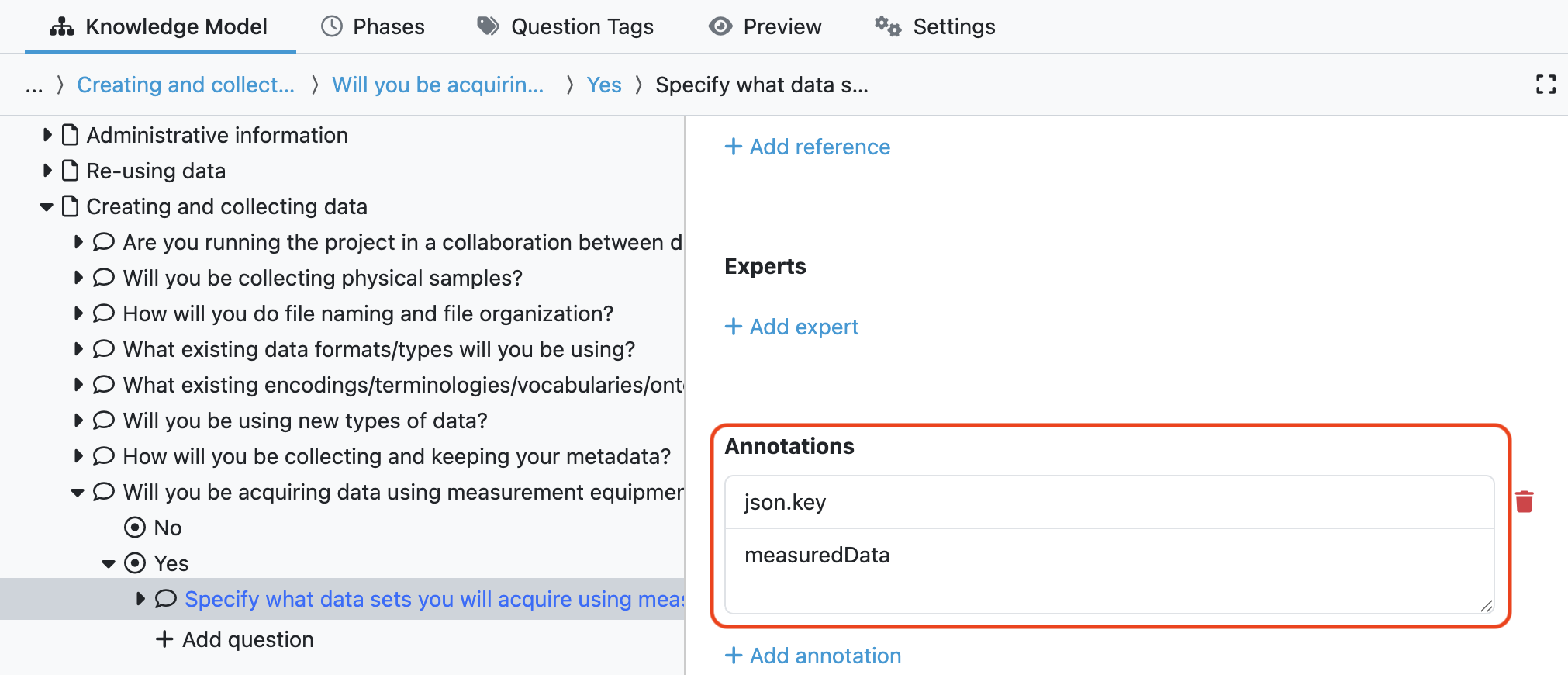
Your templates now access structured data as:
data.dmp.datasets.hasMeasured.measuredData._value
instead of:
{% set repliesMap = ctx.questionnaire.replies %}
{% set measuredPath = [uuids.creatingCUuid, uuids.measuredQUuid, uuids.measuredYesAUuid, uuids.measuredDataQUuid]|reply_path %}
{% set measured = repliesMap[measuredPath]|reply_str_value %}
✅ KM Annotations define what data is mapped into which structured field.
✅ A mapping layer transforms raw questionnaire context into clean, structured JSON-like objects for use in templates.
✅ Document templates use clean Jinja logic to iterate and render structured data without boilerplate.
The new template style is very useful, especially for complex and nested Knowledge Models.
{% if data.dmp.datasets.measured %}
<ul>
{% for dataset in data.dmp.datasets.measured %}
<li>
<strong>{{ dataset.name }}</strong>
{% if dataset.description %}: {{ dataset.description }}{% endif %}
{% if dataset.collectedBy %}
<br>Collected by: {{ dataset.collectedBy }}
{% endif %}
{% if dataset.equipment %}
<br>Equipment: {{ dataset.equipment }}
{% endif %}
{% if dataset.utility %}
<br>Expected utility: {{ dataset.utility }}
{% endif %}
</li>
{% endfor %}
</ul>
{% else %}
<p>No measured datasets identified yet for this project.</p>
{% endif %}
✅ Readable and declarative
✅ Easy to extend (e.g., add ownership, accessibility notes)
✅ Reusable across multiple document outputs (DMP, Executive Summary)
You can read the specification in FAIR Wizard User Guide.
Simplicity: No more manual UUID hunting or fragile path constructions.
Maintainability: Changes in KM structure require updating annotations and mappings, not templates.
Reusability: The same structured mapping serves multiple outputs.
FAIRness: Enables clarity and auditability in document generation, essential for transparent data governance.
With this structured, annotation-driven approach, you can:
✅ Stop maintaining UUID jungles in your templates.
✅ Start annotating systematically, mapping cleanly, and templating clearly.
✅ Result: More scalable FAIR Wizard workflows, higher quality documentation, and better collaboration across funders, projects, and teams.
Need to refactor your DMP templates to this advanced structured style? Create clean internal onboarding materials for your team? Or would you like to get training on this new system also usable in Data Stewardship Wizard?